n8n 工作流跑通一次不难,难的是长期稳定运行。真正交付给客户或自己长期使用时,问题一定会出现:接口超时、表单字段为空、模型返回异常、邮件发送失败、Webhook 重复触发、第三方服务限流。
如果没有错误处理,自动化流程就会变成“看起来自动,坏了全靠人发现”。所以 n8n 工作流上线前,必须设计失败后的重试、告警和人工兜底。
如果你刚开始搭 n8n,可以先看 n8n 自动化工作流完整教程 和 n8n Webhook 教程。本文更偏运维和交付,适合结合 AI智能体与自动化专题、AI工具评测专题 一起看。
先分清三类失败
不要把所有失败都当成同一种问题。n8n 里常见失败大致可以分三类。
第一类是临时失败。比如接口超时、网络抖动、对方服务偶发 500、模型响应太慢。这类失败适合自动重试。
第二类是数据失败。比如表单缺字段、邮箱格式错误、客户选择了不存在的套餐、上传文件格式不对。这类失败不应该盲目重试,而应该记录错误并通知人工修正。
第三类是业务失败。比如线索评分太低、客户问题需要人工审核、退款或合同条款不能自动处理。这不是技术错误,而是流程边界,需要进入人工处理队列。
先分类,后处理。否则你会把本该人工判断的问题反复重试,把本该自动恢复的问题变成夜里告警。
关键节点要设置超时和重试
凡是调用外部服务的节点,都应该考虑超时和重试。尤其是 HTTP Request、AI 模型调用、邮件发送、飞书/企业微信通知、数据库写入。
建议遵守三个原则:
- 重试次数不要太多:通常 2-3 次够了,避免把对方接口打得更慢。
- 重试要有间隔:不要失败后立刻连续请求,给外部服务恢复时间。
- 只重试临时错误:参数错误、权限错误、字段缺失,重试也不会成功。
如果一个节点经常超时,不要只加重试。还要检查输入数据是否过大、模型提示词是否太长、接口是否限流、是否需要把大流程拆成多个小流程。
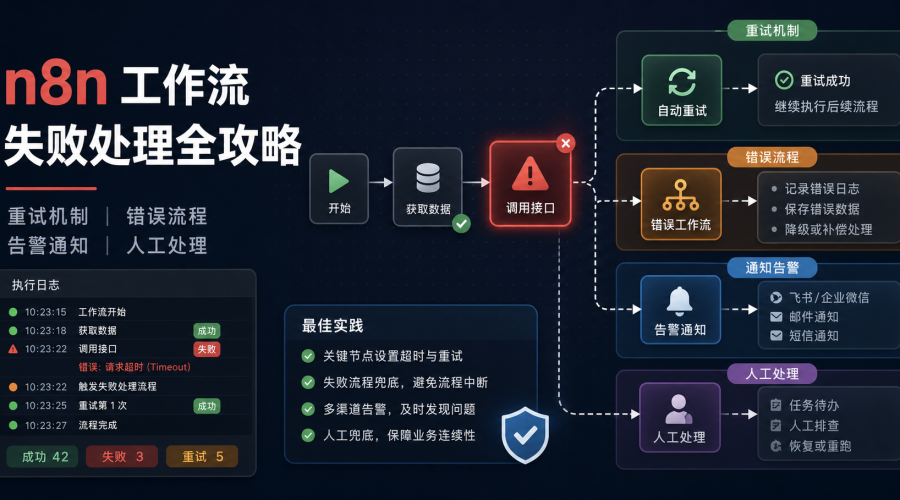
用错误流程兜住异常
n8n 的 Error Workflow 思路,是让主流程失败后触发一个专门处理错误的流程。这个错误流程不负责完成原任务,而是负责记录、通知和分流。
一个实用的错误流程可以包含这些步骤:
- 接收失败流程名称、节点名称、错误信息和执行 ID;
- 把错误写入表格、数据库或日志系统;
- 按严重程度判断是否需要通知;
- 发送飞书、企业微信、邮件或短信告警;
- 把需要人工处理的任务放入待办列表。
这和 n8n AI 日报自动化、Dify 和 n8n 组合交付方案 的思路是一样的:自动化不是不需要人,而是把人放在关键节点上。
告警不要只发“失败了”
很多 n8n 告警没用,是因为通知内容太少。只发一句“工作流失败”,人工还要打开后台一点点查。
更好的告警至少包含:
- 工作流名称;
- 失败节点;
- 错误摘要;
- 输入来源或客户标识;
- 执行链接或日志位置;
- 建议动作:重跑、补数据、联系客户、忽略。
告警的目标不是“让人知道出错”,而是让人能尽快判断下一步。对个人项目来说,飞书或邮件足够;对客户项目来说,可以按严重程度分成普通提醒和紧急通知。
人工兜底要提前设计
很多自动化项目失败,不是技术没跑通,而是失败后没人接。比如 AI 客服无法回答、表单缺字段、客户上传资料不完整,如果没有人工兜底,用户体验会断掉。
建议给每个关键流程设计一个“人工处理出口”:
- 线索自动分类失败,进入人工审核表;
- AI 回答置信度低,转给人工客服;
- 报价条件不完整,发提醒让销售补充;
- 文件处理失败,保留原文件并通知负责人;
- 连续重试失败,停止自动重跑,等待人工判断。
这类设计也适合和 AI Agent 人机协作流程 一起看。真正稳定的 AI 自动化,通常不是全自动到底,而是自动处理常规情况,人工接住异常情况。
上线前做一次故障演练
不要等真实客户触发错误才检查流程。上线前可以故意制造几种失败:
- 让 HTTP 接口返回错误状态;
- 删除一个必填字段;
- 填入超长文本或异常文件;
- 断开某个账号授权;
- 让通知节点发送到测试群。
检查重点不是“有没有失败”,而是失败后有没有被记录、有没有通知到人、通知内容是否足够处理、是否会重复触发造成消息轰炸。
老达点评
n8n 最大的价值,是把零散工具连接成流程。但流程越长,失败点越多。只会搭节点的人,交付的是演示;会处理失败的人,交付的才是系统。
我的建议是:每个 n8n 工作流上线前,都问三个问题:哪些错误可以自动重试?哪些错误必须通知人工?哪些错误要停止流程避免扩大影响?这三个问题想清楚,n8n 才能从“能跑”走到“可靠”。