很多人搭 n8n AI Agent 工作流时,第一版能跑起来,但很快会遇到一个问题:用户连续问几轮以后,AI 记不住前面说过什么;换一个客户咨询,又可能把上一位客户的上下文带进来。这个问题不是模型够不够聪明,而是记忆配置没有设计好。
n8n 里的 AI Agent 记忆,最关键的不是“让 AI 记住越多越好”,而是让它在正确的会话里记住正确的信息。今天这篇就围绕 Session Key、Simple Memory、上下文窗口和人工审核,讲一套适合个人项目和小团队的配置思路。
先理解:n8n 记忆不是知识库
很多新手会把 Memory 和知识库混在一起。简单说:
- 知识库:存放产品说明、FAQ、文档、价格表,适合长期检索。
- 会话记忆:保存当前用户这次或最近几次对话上下文,适合多轮对话。
如果用户问“这个套餐多少钱”,应该走知识库或数据库;如果用户上一轮说“我是餐饮店老板”,下一轮问“那我适合哪种方案”,这时才需要会话记忆。
这和 AI智能体与自动化专题 里反复强调的一点一样:AI Agent 的稳定性,不只靠模型,而靠上下文、工具和流程的边界。
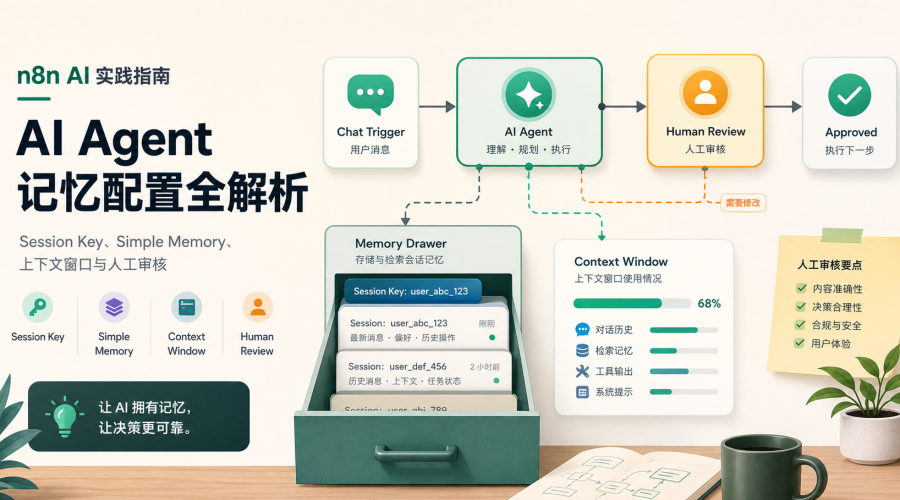
Session Key 是记忆配置的核心
Session Key 可以理解为“这段记忆属于谁”。如果 Session Key 设计错了,轻则 AI 记不住用户上下文,重则不同用户的会话混在一起。
常见做法是根据入口选择不同的 Session Key:
- 聊天入口:用用户 ID、聊天 ID 或会话 ID。
- 表单入口:用提交记录 ID、手机号哈希或邮箱哈希。
- 客户跟进入口:用 CRM 客户 ID 或线索 ID。
不要用一个固定值给所有用户共用。比如所有会话都叫 default,看似方便,实际会让不同人的上下文混成一团。
Simple Memory 适合哪些场景
n8n 的 Simple Memory 适合做轻量会话记忆,比如:
- 客服连续追问:用户前面说了预算、行业、目标,后面继续追问方案。
- 线索初筛:AI 需要记住用户已经提供过的公司规模、需求类型、联系方式。
- 内容助手:用户连续修改标题、摘要、风格,AI 需要保留当前版本偏好。
但它不适合当作长期客户数据库,也不适合存放必须审计的交易记录。涉及订单、报价、合同、付款、隐私信息时,应该写入表格、CRM 或数据库,再由 AI 读取必要字段。
如果你还没有搭过基础流程,可以先看 n8n AI Agent 工作流教程,再回来看记忆配置会更容易理解。
一个实用配置流程
第一步:确定入口字段
先确认工作流从哪里触发:Chat Trigger、Webhook、表单、客服消息,还是手动测试。入口不同,可用的用户标识也不同。
例如表单线索自动化,可以把提交记录 ID 作为 Session Key;聊天机器人可以用用户 ID 加渠道 ID,避免同一个用户在不同渠道的上下文互相污染。
第二步:接入 AI Agent 和 Simple Memory
在 AI Agent 节点里接入 Memory,选择 Simple Memory,并把 Session Key 映射到前一步得到的用户或会话字段。这里不要手填固定字符串,最好使用表达式从输入数据里取值。
第三步:控制上下文窗口
记忆不是越长越好。上下文太短,AI 会忘;上下文太长,成本增加,也可能把旧意图带入新任务。个人项目可以先保守一点,只保留最近几轮关键对话,再根据实际效果调整。
第四步:把关键事实结构化保存
会话记忆适合保留对话上下文,但关键事实最好另存一份。比如客户行业、预算、交付期限、联系方式、是否需要人工跟进,可以写入表格或 CRM。这样后续工作流不依赖“AI 记得”,而是读取明确字段。
这一步可以和 n8n 表单获客自动化 结合:表单负责收集字段,AI 负责分类和补充判断,人工审核负责最后确认。
人工审核要放在哪里
只要 AI Agent 会根据记忆做对外回复、报价建议或客户分级,就应该保留人工审核。尤其是下面几类场景:
- AI 根据历史对话判断客户意向等级;
- AI 生成报价、承诺交付时间或服务范围;
- AI 要触发邮件、飞书、微信或 CRM 跟进动作;
- AI 读取了包含个人信息或商业信息的数据。
人工审核不一定要很重,可以只是一个“待确认”节点、一张表格状态、一条飞书提醒。关键是不要让 AI 在记忆可能有误的情况下直接执行高风险动作。
常见坑
坑一:Session Key 太粗
所有用户共用一个 key,会导致上下文串线。最低限度也要做到一个用户或一个会话一个 key。
坑二:把记忆当数据库
记忆适合帮助 AI 理解上下文,不适合承载严肃业务记录。该写表格、数据库或 CRM 的信息,不要只放在 Memory 里。
坑三:没有清理和复位机制
有些会话过期后应该重新开始。比如用户三个月后再次咨询,旧上下文可能已经不准确,这时需要重新确认关键字段。
坑四:上线前只测单人对话
记忆配置一定要测多人、多轮、断开后继续、换渠道咨询这几种情况。否则测试时看起来很顺,上线后才发现串线。
上线检查清单
- Session Key 是否来自真实用户、会话或线索字段。
- 不同用户测试时,AI 是否不会互相读取上下文。
- 上下文窗口是否不会把很久以前的旧需求带入当前回复。
- 关键事实是否写入表格、CRM 或数据库,而不是只存在记忆里。
- 高风险回复和执行动作是否有人工审核。
- 日志里能否追溯 AI 使用了哪些输入和工具输出。
老达点评
n8n AI Agent 的记忆配置,本质上是在回答一个问题:这段上下文属于谁、能用多久、能不能直接影响后续动作。把这三个问题想清楚,比盲目增加工具节点更重要。
我的建议是:第一版先用 Simple Memory 做短期会话记忆,用表格或 CRM 保存关键事实,再加一层人工审核。等流程稳定以后,再考虑更复杂的长期记忆、向量检索和 MCP 工具调用。你也可以继续看 普通人AI实践专题 和 AI Agent 任务队列设计,把记忆、任务状态和人工确认连起来。



