如果你还在用 Chat Completions API 做对话、客服、写作助手或自动化工具,现在该认真看一下 OpenAI Responses API 了。它不是简单换一个接口名字,而是把多轮状态、工具调用、多模态输入和 Agent 工作流放到一个更统一的 API 形态里。
老达之前写过 OpenAI Codex 最新进展,里面提到 AI 编程助手正在从“聊天工具”走向“能执行任务的 Agent”。Responses API 也是同一条主线:模型不只是回答文字,而是在一次请求里组织工具、上下文和结果。
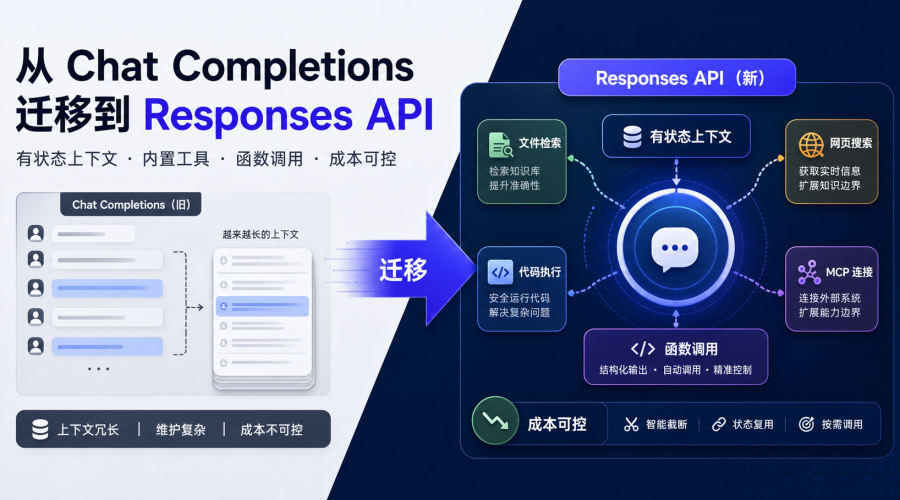
Responses API 和 Chat Completions 最大区别是什么
Chat Completions 的核心对象是 messages。你把 system、user、assistant 消息拼成数组,自己维护上下文,然后把整段历史继续传给模型。
Responses API 的核心对象更接近“任务过程”。输入不只是一组聊天消息,还可以包含工具调用、函数调用结果、多模态内容和上一次 response 的引用。官方迁移文档明确提到,Responses 是面向 agent-like applications 的统一接口,并推荐新项目优先使用它。
用开发者能听懂的话说:如果你的应用只是一次性问答,Chat Completions 还能用;如果你要做多轮任务、文件检索、网页搜索、代码执行、MCP 连接或函数工具调用,Responses API 更适合作为新的基础接口。
这类变化和 OpenAI专题、AI智能体与自动化专题 里的趋势一致:大模型 API 正在从“补全文本”走向“调度工具”。
最小迁移:从 messages 改到 input
如果你没有函数调用、没有复杂多模态、没有长期状态,迁移第一步其实不复杂:把 /v1/chat/completions 改成 /v1/responses,把 messages 改成 input,再从 response.output_text 取结果。
import OpenAI from "openai";
const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
const response = await client.responses.create({
model: "gpt-5",
instructions: "你是一个严谨的中文技术编辑。",
input: "把这段产品说明改成更适合官网的中文文案。"
});
console.log(response.output_text);
这里有一个很实际的变化:instructions 可以承担系统级指令,input 承担用户输入。对内容工具、内部知识库和客服机器人来说,这比把所有内容塞进 messages 更清晰。
多轮对话:不要再无脑拼完整历史
很多项目用 Chat Completions 时,会把历史消息一轮轮拼长。短期能跑,长期会遇到三个问题:上下文越来越贵、截断逻辑越来越复杂、工具调用结果混在聊天消息里越来越难维护。
Responses API 支持通过上一轮 response id 串联上下文。对普通开发者来说,思路可以变成:
- 短任务:直接传
input,不保存状态。 - 连续任务:保存上一轮
response.id,下一轮用previous_response_id接上。 - 敏感任务:明确设置存储策略,必要时关闭服务端保存。
这并不代表你完全不用设计上下文。相反,你更应该把用户资料、业务数据、检索结果和工具结果分层处理,而不是全部当作聊天记录硬塞进去。
工具调用:Responses API 真正适合 Agent 的地方
Responses API 的重点不只是文本生成,而是工具。官方文档列出的方向包括 web search、file search、computer use、code interpreter、remote MCPs,以及自定义函数。对开发者来说,这意味着你可以围绕一个任务请求,让模型自己决定什么时候调用工具、什么时候汇总结果。
举个例子,如果你做一个“站内文章改写助手”,旧做法可能是:
- 先让后端查数据库;
- 再把文章、关键词和规则拼进 prompt;
- 模型输出后,再由后端解析结果;
- 如果需要查旧文链接,再额外请求一次。
迁移到 Agent 工作流后,可以把站内搜索、文章读取、SEO 检查、图片生成、发布后检查拆成工具。模型不再只生成正文,而是在权限边界内完成一串动作。这和 MCP 工作流入门路线 里讲的思路非常接近。
什么时候应该迁移到 Responses API
我建议用下面这张判断表:
- 只是简单问答或低频脚本:可以先不急,继续维护现有 Chat Completions。
- 新项目:优先用 Responses API,减少以后再迁移一次。
- 需要多轮任务状态:优先评估 Responses API。
- 需要文件检索、网页搜索、代码执行或 MCP:优先用 Responses API。
- 已有大量函数调用:先做一条小链路迁移,验证输入输出和错误处理,再逐步替换。
如果你做的是个人站长工具、AI内容流程、客服知识库或自动化运营系统,也可以参考 邮箱远程调度 Codex 的异步工作流。这些应用的共同点是:真正有价值的不是一次回答,而是跨工具完成任务。
迁移时最容易踩的 4 个坑
第一,只改接口,不改数据结构。 如果你仍然把所有内容当作 messages 拼接,只是外面换成 Responses,很难发挥它的价值。至少要把系统指令、用户输入、工具结果、检索内容分开。
第二,忽略存储和隐私策略。 多轮状态方便,但不是所有任务都适合默认保存。涉及用户隐私、企业资料、客户合同、内部代码时,要明确哪些内容可以保存,哪些必须关闭或脱敏。
第三,工具权限太宽。 Agent 能调用工具,不代表每个工具都应该开放写权限。读取、搜索、草稿生成可以更开放;发布、删除、支付、发邮件、改数据库应该加人工审核。
第四,没有成本观测。 官方迁移文档提到 Responses 在缓存利用上有成本优势,但落到项目里,仍然要记录输入 token、输出 token、工具调用次数、重试次数和失败原因。否则你只知道“能跑”,不知道“贵在哪里”。
适合小团队的迁移路线
不要一口气重写所有 API。更稳的方式是先选一个低风险但有代表性的功能,比如“文案生成”“文章摘要”“FAQ 改写”或“站内旧文推荐”。
- 先把一次性生成接口从 Chat Completions 改到 Responses。
- 确认输出字段、错误处理、日志记录和超时策略。
- 再加入一个工具,比如站内搜索或文件检索。
- 最后才处理多轮状态、MCP、后台任务和人工审核。
这样做的好处是,迁移过程不会影响主业务。你可以把 Responses API 当成新工作流的地基,而不是一次性替换所有旧接口。
老达点评
OpenAI Responses API 的方向很清楚:以后做 AI 应用,重点会从“怎么拼 prompt”转向“怎么组织状态、工具、权限和结果”。这对普通开发者是机会,也是门槛。
机会在于,小团队也能用更统一的 API 做出像 Agent 一样的产品体验;门槛在于,工程设计不能再停留在一个 prompt 加一个输出框。你需要考虑工具边界、日志、成本、失败重试和人工确认。
如果你只是做内容生成,不必焦虑。但如果你正在做 AI 客服、知识库问答、自动化运营、代码助手或站内工具,我建议从今天开始用一个小功能试迁移。未来真正值钱的,不是单次调用模型,而是把模型接进稳定可控的业务流程。更多工具选型可以继续看 AI工具评测专题 和 Codex、API、OpenClaw、Claude Code 成本对比。




0 条评论